Member-only story
Tesla AI Day
Deep Understanding Tesla FSD Part 4: Auto Labeling, Simulation
From Theory to Reality Analyze the Evolution of Full Self-Driving from Tesla AI Day

This is the third article in my series on Deep Understanding Tesla FSD.
- Deep Understanding Tesla FSD Part 1: HydraNet
- Deep Understanding Tesla FSD Part 2: Vector Space
- Deep Understanding Tesla FSD Part 3: Planning & Control, Auto Labeling, Simulation
- Deep Understanding Tesla FSD Part 4: Labeling, Simulation, etc
In the previous articles, we discussed how does Tesla makes a car autonomous?
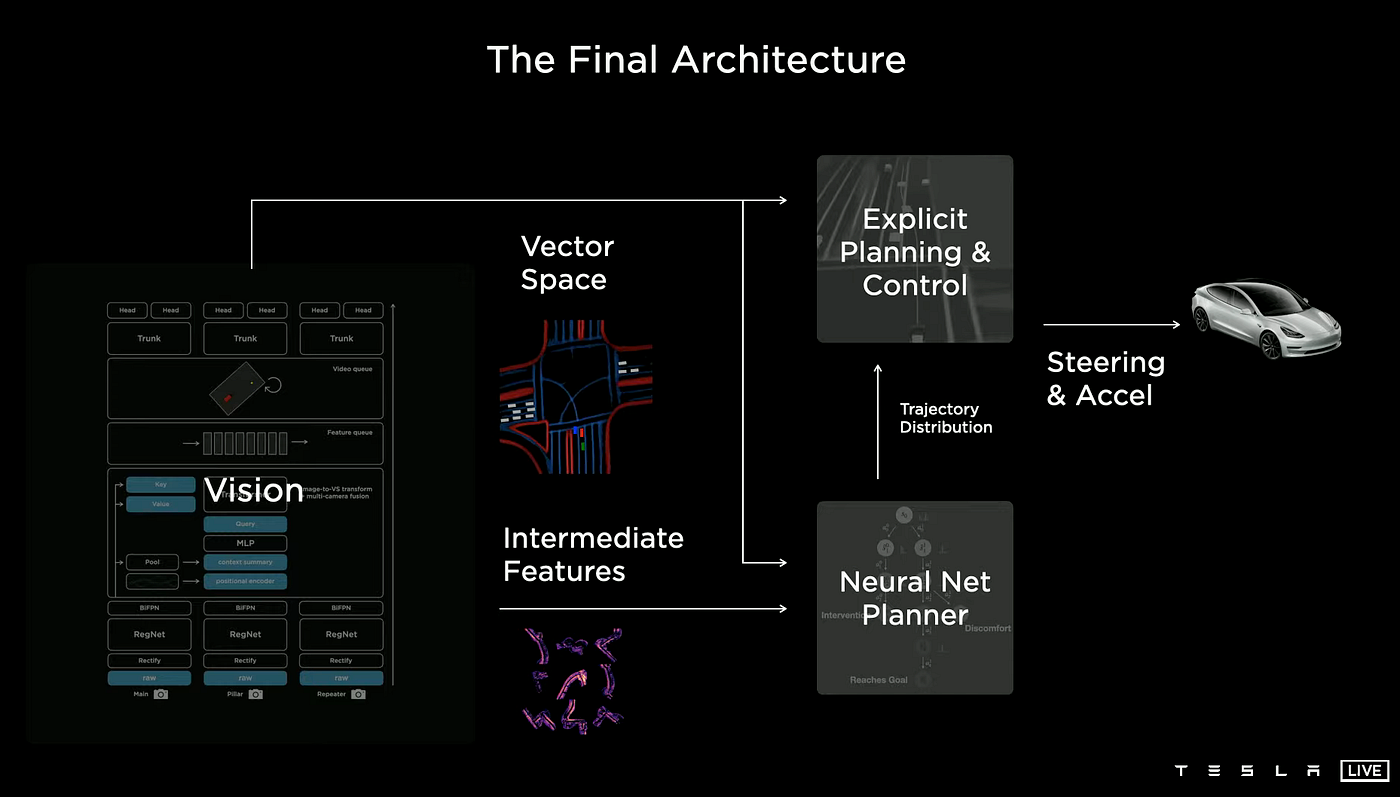
Up to now, we know that the Tesla AI team has a nearly perfect vision module, Vector Space, many advanced and new AI models, planning, and control systems. In order to train these neural networks in this architecture, the Tesla AI team also needs a large, efficient, and comprehensive data set.
In this article we will talk about: Labeling, Simulation, Scaling Data Generation, AI Compiler & Scheduling, Tools & Evaluations, etc.
The neural networks only establish an upper bound on your performance. — Andrej Karpathy
How Does Tesla Generate training data?
Manual Labeling

In order to obtain high-quality labels and uphold the spirit of full vertical integration at Tesla, Tesla has a 1,000 person in-house data labeling team.
As we mentioned in earlier articles, Tesla developed a vector space and made predictions on the vector space. Tesla AI needs to accumulate millions and millions of vector space examples that are clean and diverse to actually train these neural networks effectively.
